
Introduction
The Lightning Network consists of a vast collection of two-way payment channels. As discussed in the onion-routing blog post, the sender must choose a route for the payment on the network, a task known as pathfinding. Interestingly, pathfinding is not defined in any of the BOLTs (Basics of Lightning Technology), because it’s a self-contained task. Unlike opening and closing channels, which require coordination and interoperability, pathfinding doesn’t. Each node or wallet can select its strategy for this process.
Today, with so many nodes and payment channels in the network, finding a path for payment is easy. The real challenge is choosing the best path among thousands of possibilities. By “best,” we typically mean a path with enough available funds, low fees, and short timelocks. Finding a route that excels in all these areas is quite tricky. Pathfinding algorithms often aim to find a balanced solution, making compromises among these factors.
Besides the particularity of each pathfinding algorithm used in different nodes and wallets, they usually stand by the same foundational blocks. That is:
- Creating a “map” of the network, known as a channel graph, using the gossip messages.
- Finding paths that connect sender and recipient.
- Filter and order these paths based on some set of preferences
- Try each path until payment succeeds.
- Update the channel graph based on information gained trying paths so other payments have a better chance of success.
Creating the Channel Graph
A graph is made up of edges and vertices. In the Lightning Network, each node is considered a vertex, and each payment channel is an edge connecting two nodes. Nodes must create a network graph to select the right channels for sending payments. A node monitors messages broadcast over the network to build and update this channel graph.
When a new node joins the Lightning Network, it sends out a ‘node_announcement’ message with details about itself. This message helps in creating the vertices of the channel graph. When a new public channel is formed, a ‘channel_announcement’ message is broadcast, including the channel’s capacity and ID. This information helps in creating the edges that connect the vertices. Lastly, when nodes update their policies, they send a ‘channel_update’ message containing details about fees and timelocks for the payment channel. This adds cost information used to calculate the expense of sending a payment through that edge.
It’s important to note that there’s no single “channel graph” for the entire Lightning Network. Each node has its perspective on the network. Newer nodes might have less information because they have been exposed to fewer details. In comparison, older nodes will likely have a more comprehensive understanding of the network due to their longer presence and the greater information they have gathered.
Imperfect information
The channel graph provides essential information for routing payments, but some details remain unknown to the nodes. Specifically, while the capacity of payment channels is known, the liquidity distribution within a channel is not shared. This is for two main reasons:
- Preserving Privacy: Broadcasting liquidity updates would allow people to track how funds move within the network, revealing information about where money is flowing.
- Avoiding Information Overload: Sharing liquidity updates of payment channels would overflow the network with thousands of messages, especially as the network grows, leading to excessive communication that could hinder performance.
Learning as you go
Even though nodes lack information about how liquidity is divided within a payment channel, they can still learn from the outcomes of attempted payments. For example, suppose a payment fails, and a specific error (“temporary channel failure”) is returned. In that case, the node can deduce that there likely isn’t enough liquidity in that channel to route the payment. This experience then adds to the node’s understanding of the channel graph, helping to refine future pathfinding efforts.
On the other hand, if a payment succeeds, the node knows that the amount sent moves from one side of the payment channels it used to the other. It can also use this information to update its channel graph and enhance its pathfinding capabilities for further payments.
A Practical Example
Let’s say Alice just joined the network. Let’s join in as her node synchronizes with the channel graph:
From the node_announcement messages, her node creates the vertices of the channel graph:
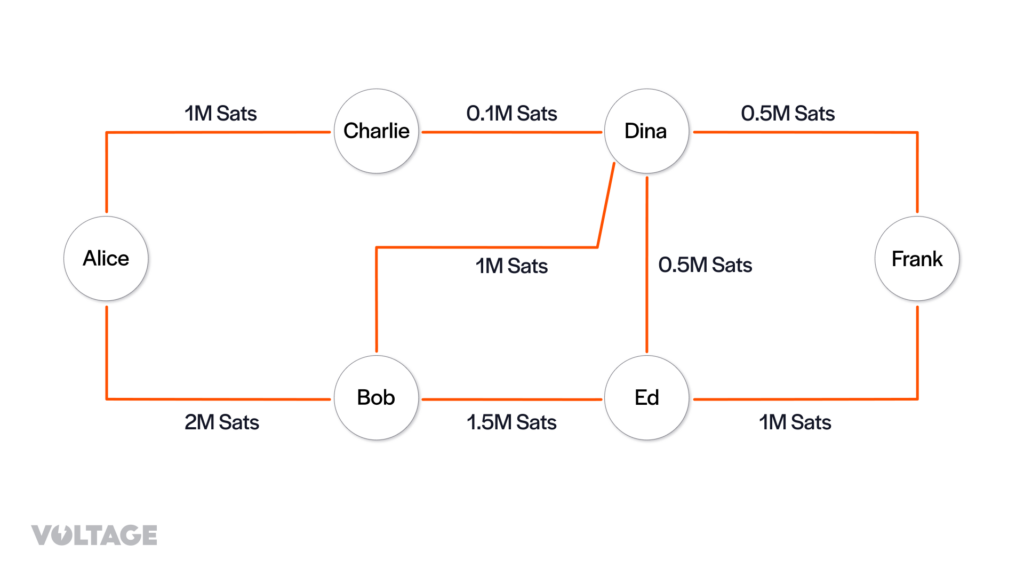
Then, from the channel_annoucement messages her node creates the edges of the channel graph:
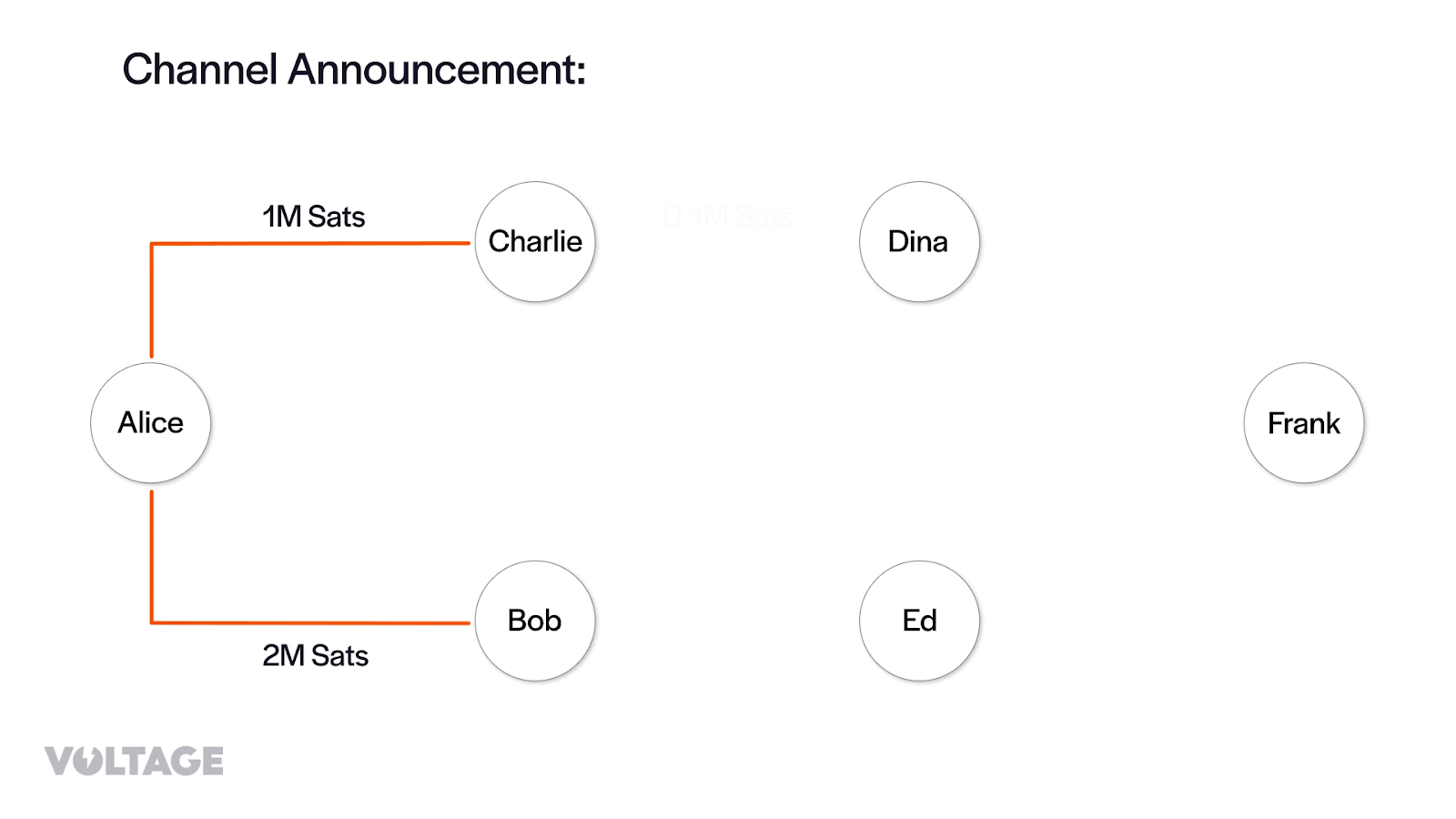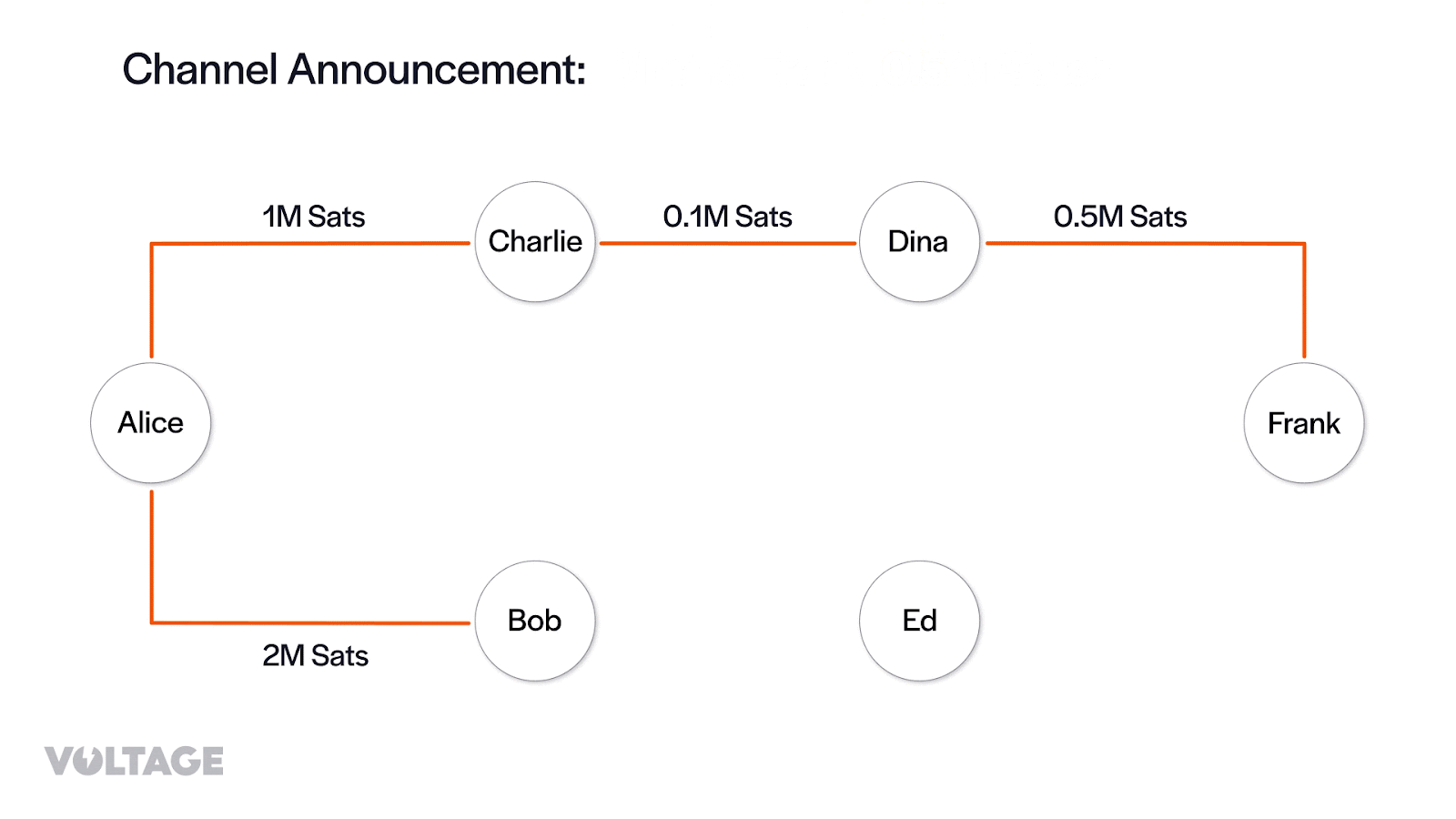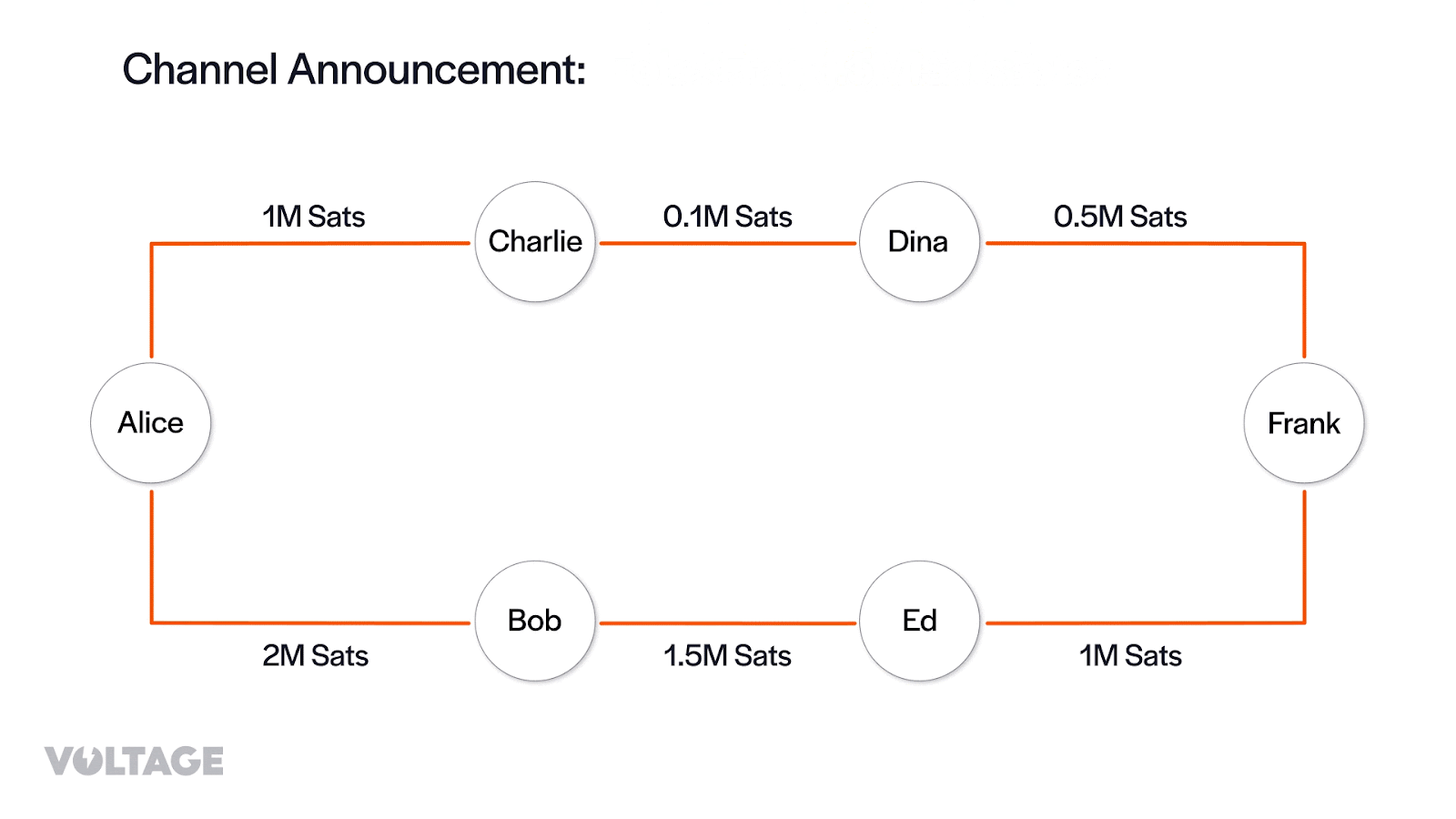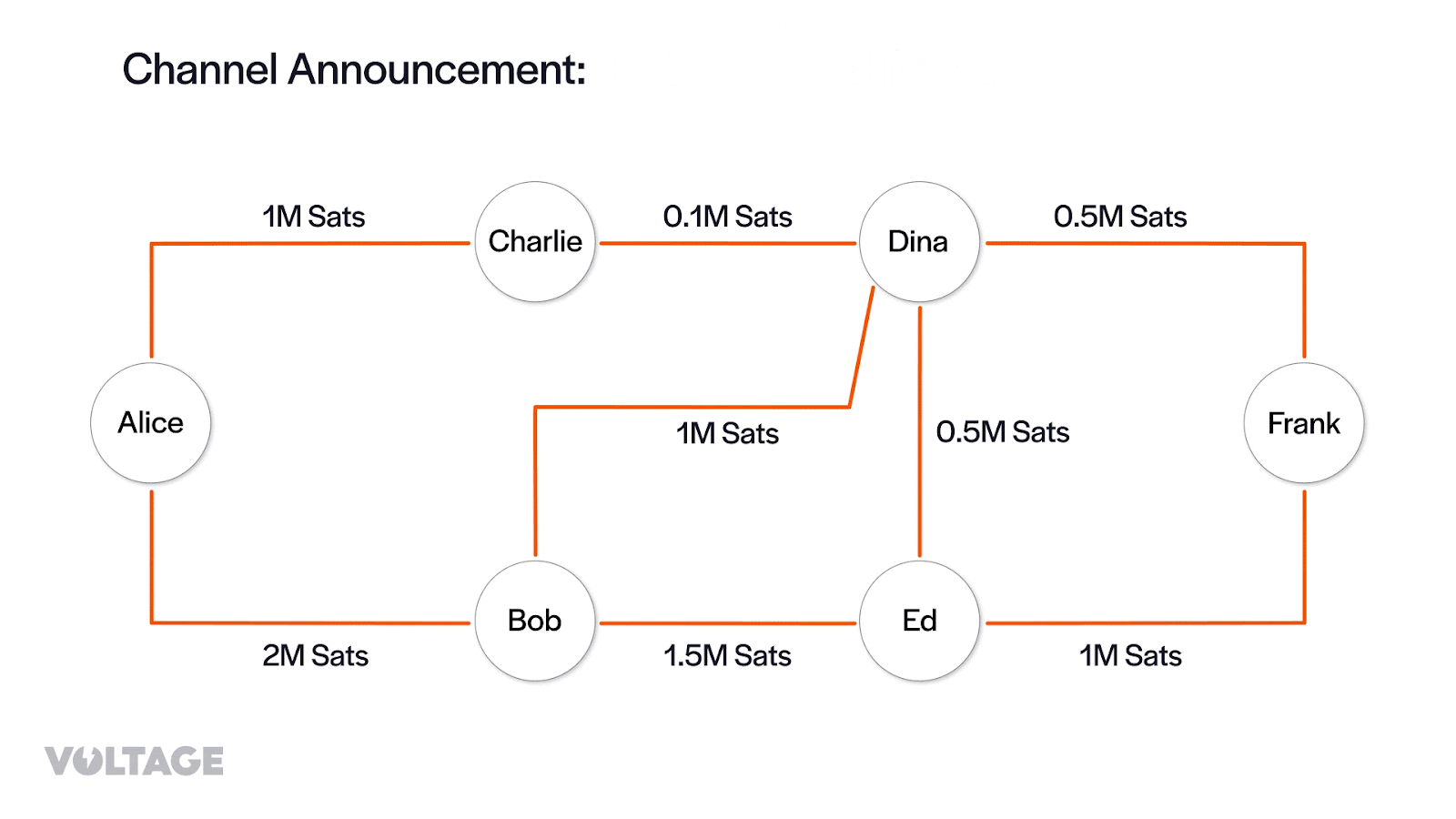
Finally, from the channel_update messages, her node adds information about fee policy and timelocks for a given edge, which can be interpreted as the cost of traversing the edge.

Remember that Alice knows how liquidity is distributed in her channels since they belong to her. However, she doesn’t know how liquidity is distributed in other channels. She’ll gradually learn more about those channels as she attempts to send payments through them.
Finding Paths
With the channel graph in sync, the node can choose paths for sending the payment. The complexity of this task varies based on factors like the distance between sender and recipient (the minimum number of hops needed), the fees the sender is willing to pay, and the acceptable timelock for funds to return if a payment gets stuck. The more aspects the user wants to optimize, the more challenging it becomes to find suitable paths for payment.
Keep in mind that while each node can implement pathfinding in its unique way, some principles remain constant. For example, the search must always be conducted backward, from the receiver to the sender. This approach accounts for the fees accumulated along the path from the recipient to the sender, ensuring that the correct costs are factored into the route selection.
Back to our Example
Now, let’s say that Alice wants to pay Frank 0.4M sats. From the channel graph, the node selects the possible paths that can be used to route the payment.
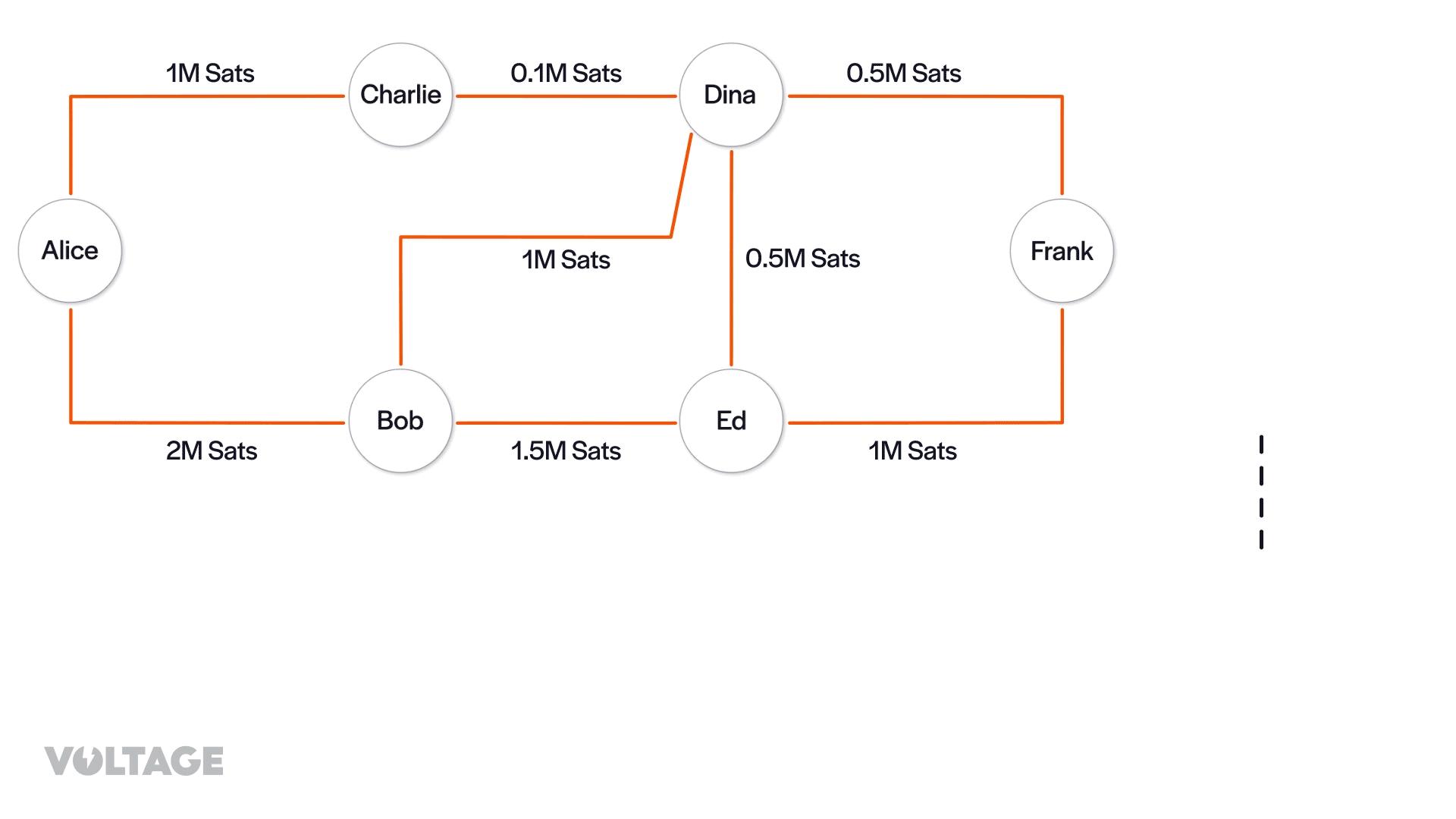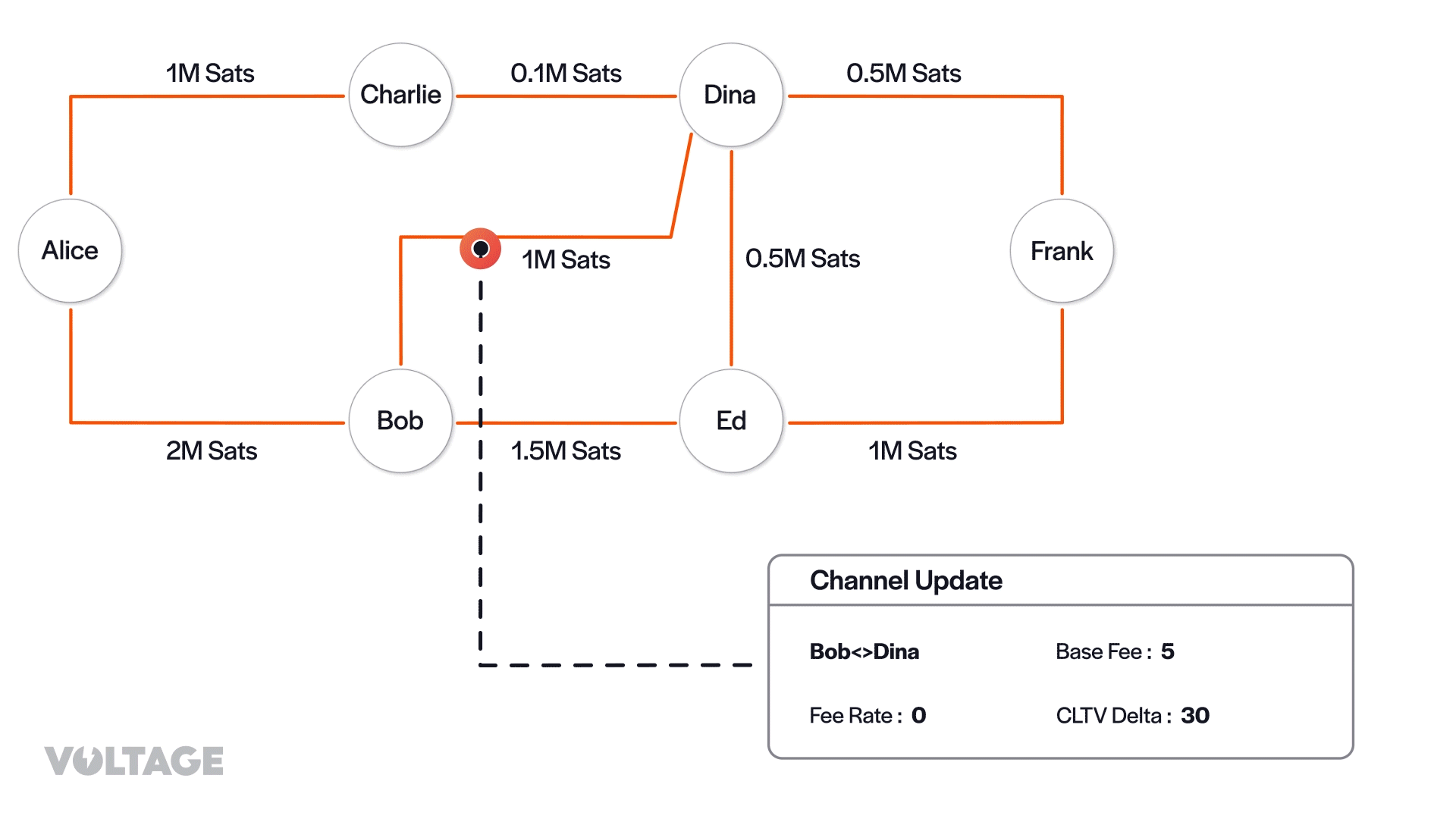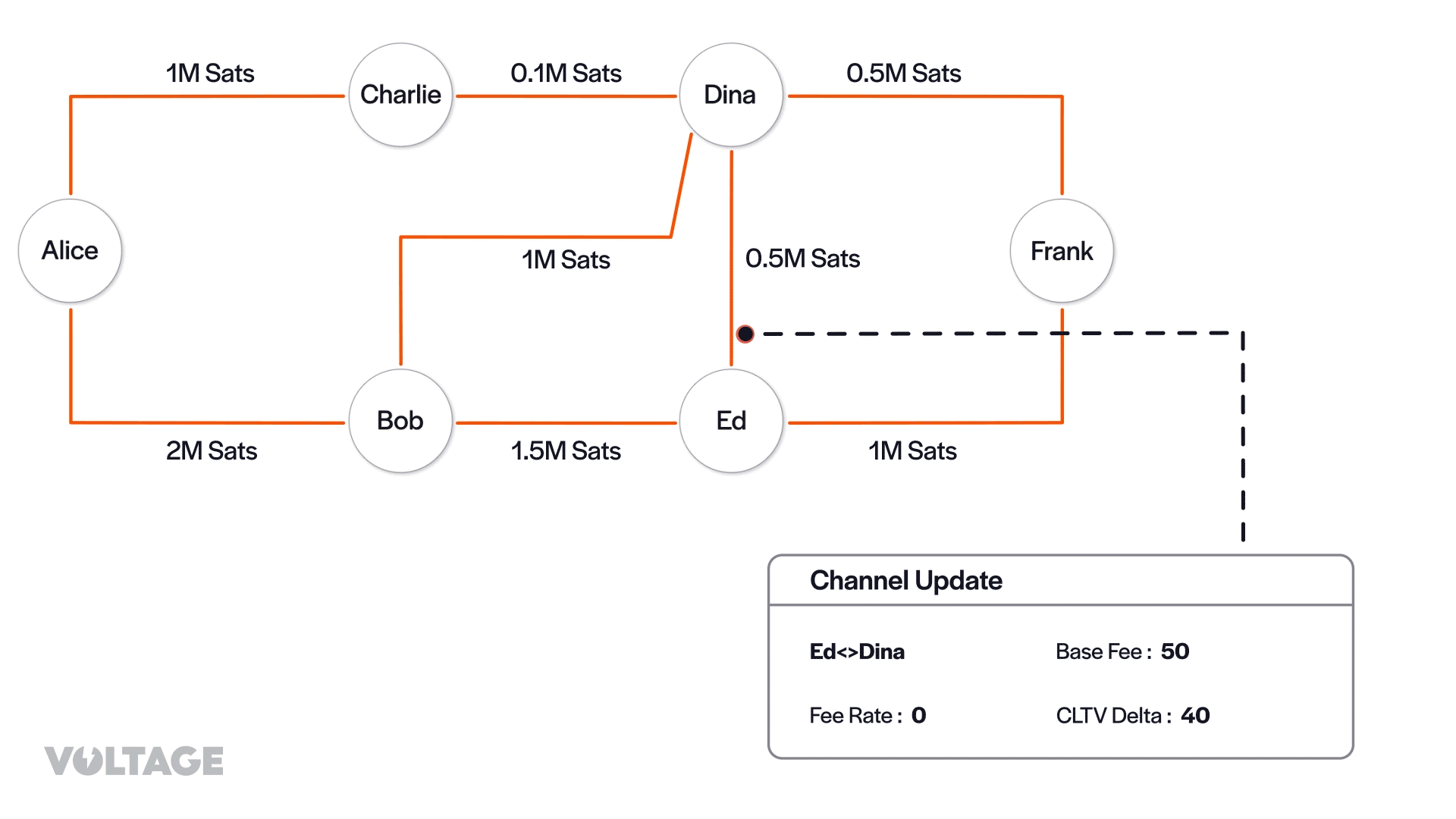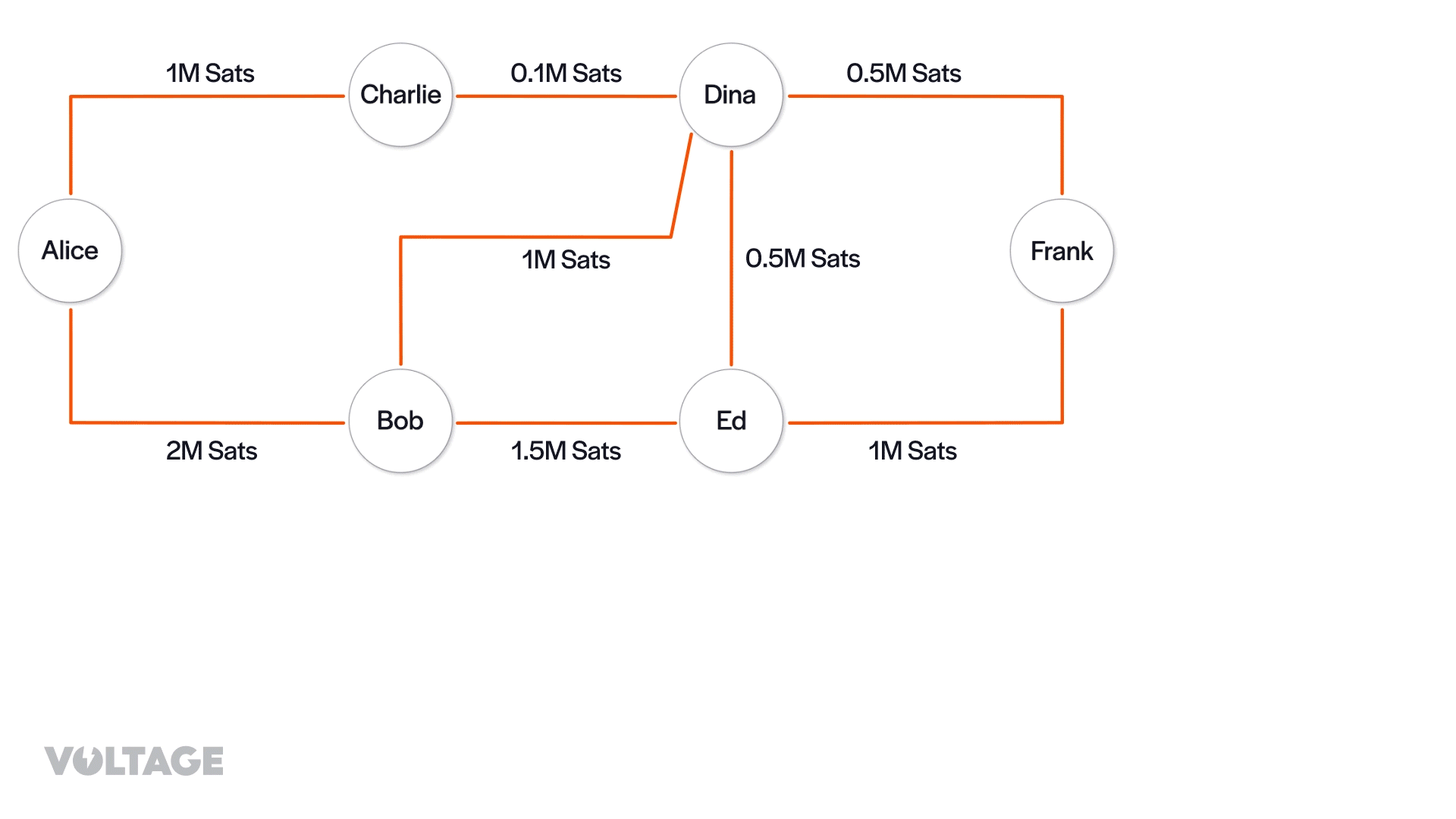
- Alice → Bob → Ed → Frank
- Alice → Bob → Ed → Dina → Frank
- Alice → Bob → Dina → Frank
It’s worth noting that there’s another path (Alice → Charlie → Dina → Frank), but Alice’s node won’t consider this route. The channel from Charlie to Dina lacks the capacity to handle the payment, so it’s automatically ruled out.
Alice’s node can now optimize the path selection based on criteria like fees or timelocks. To simplify, let’s assume Alice wants to minimize fees. Her node will then prioritize the paths by arranging them in ascending order of total fees. Note that the first hop doesn’t incur fees and that all fee rates are equal to zero. Therefore, we only need to account for base fees.
- Alice → Bob → Dina → Frank (5 + 10 = 15)
- Alice → Bob → Ed → Frank (20 + 15 = 35)
- Alice → Bob → Ed → Dina → Frank (20 + 50 + 10 = 80)
Sending The Payment
In this process step, the node will try to send the payment through each route listed on the previous step. If the payment delivery fails, it’ll proceed to the next path on its list. On the other hand, if the payment succeeds, then its job is done. For a given payment attempt, there are three possible outcomes:
- A successful result;
- An error;
- A “stuck” payment with no response;
In success and error cases, the node gains extra information about the channels used in the payment, as discussed before. This trial-and-error loop gives us insight into how probability can be used to interpret the chance of success for a given payment.
It’s all About Probability
When we talk about the chance of successfully sending a payment across channels with varying liquidity, there are a few ideas that come into play:
- Smaller payments are easier to send: If you’re trying to send a small amount of money, it’s more likely to succeed because it requires less available funds in the channel.
- Channels with more capacity work better: If a channel has more funds, you’ll have a better chance of sending a specific amount.
- More channels (hops) lower the success rate: The more channels you pass through, the more chances something could go wrong, lowering the overall success rate.
Here’s a simple way to understand how these principles work:
Think of a payment channel that has 5 BTC capacity. The liquidity on the local side of the payment channel could be 0, 1, 2, 3, 4, or 5. If you want to send 5 BTC, there’s only one way it can work (if liquidity is exactly 5), so there’s a 16.66% chance of success. If you want to send 3 BTC, the chances go up to 50% because it can work in three ways (if liquidity is 3, 4, or 5). The chances for a 1 BTC payment are even higher at 83.33%. The pattern here is simple: the smaller the amount you want to send, the greater the chance there will be enough liquidity in the channel to make the payment.
Imagine a channel with a capacity of 10 BTC instead of 5. In that case, sending 5 BTC would have a 45% chance of success, showing that higher capacity channels increase the likelihood of a payment going through. When a payment must pass through multiple channels (or “hop”), the success rate decreases. If there are two channels with the ability to send 5 BTC, the chance of successfully sending 3 BTC through both is 25%. So, each additional hop lowers the chance of a payment being successful.
Alice Sends the Payment: The Trial-and-Error-Loop
Alice’s node is set to send the payment, starting with the cheapest route (Alice → Bob → Dina → Frank). The payment successfully navigates the first two hops but fails at the last one. The error message informs Alice that there’s insufficient liquidity on that path to complete the payment. She then uses this information to update her channel graph, gaining a better understanding of that channel, which will aid in future payment attempts.
Next, the node attempts the second cheapest route (Alice → Bob → Ed → Frank). This time, all the hops have the necessary liquidity, and the payment is successfully delivered.
Improving Payment Reliability
Plenty of research is on making payments more reliable in the Lightning Network. We’ve covered that when talking about Multi-Part Payments, for instance. If you want to go deep into the payment reliability rabbit hole, I suggest reviewing Rene Pickhardt’s research papers.



